

¿Qué es y cómo funciona el «BIG DATA»? (2da parte)
Herramientas de Big Data
Como el Big Data es algo que no deja de crecer, las herramientas que se usan para gestionarlo evolucionan con él y se perfeccionan permanentemente. Se emplean herramientas como Hadoop, Pig, Hive, Cassandra, Spark, Kafka, etc., dependiendo de los requisitos de cada organización. Hay muchísimas soluciones, y buena parte de ellas son de código abierto. También hay una fundación —Apache Software Foundation (ASF)— que apoya muchos de estos proyectos sobre Big Data.
Como esas herramientas son muy importantes para el Big Data, vamos a explicar un poco en qué consisten. Quizá una de las más afianzadas para analizar Big Data sea Apache Hadoop, un marco de trabajo de código abierto para almacenar y procesar grandes conjuntos de datos.
Otro que cada vez está recibiendo más atención es Apache Spark. Una de las ventajas de Spark es que puede almacenar gran parte de los datos de procesamiento en la memoria y en el disco, así que puede ser mucho más rápido. Spark puede funcionar con el sistema de archivos distribuidos de Hadoop (HDFS), Apache Cassandra, u OpenStack Swift y muchas otras soluciones de almacenamiento de datos. Pero una de sus mejores funciones es que Spark puede funcionar en una sola máquina local y eso facilita enormemente el trabajo.
Otra solución es Apache Kafka, que permite a los usuarios publicar y suscribirse a fuentes de datos en tiempo real. La principal tarea de Kafka es trasladar la fiabilidad de otros sistemas de mensajería a los datos en streaming.
Estas son otras grandes herramientas de Big Data:
- Apache Lucene puede usarse para cualquier motor de recomendación porque utiliza bibliotecas de software de indexación y búsqueda de textos completos.
- Apache Zeppelin es un nuevo proyecto que permite el análisis de datos interactivos con SQL y otros lenguajes de programación.
- Elasticsearch es más bien un motor de búsqueda empresarial. Lo mejor de esta solución es que puede aportar conocimientos a partir de datos estructurados y no estructurados.
- TensorFlow es una biblioteca de software en auge porque se utiliza para el aprendizaje automático.
El Big Data seguirá creciendo y cambiando y, por lo tanto, las herramientas también. Y quizá dentro de unos años las construcciones que usemos sean totalmente distintas. Pero, tal como hemos dicho, algunas de las herramientas funcionan con datos estructurados o no estructurados. Veamos qué significa eso.
Tipos de Big Data
Entre los Big Data hay tres tipos de datos: estructurados, semiestructurados y no estructurados. En cada uno de estos tipos hay mucha información útil que puedes extraer para usarla en distintos proyectos.
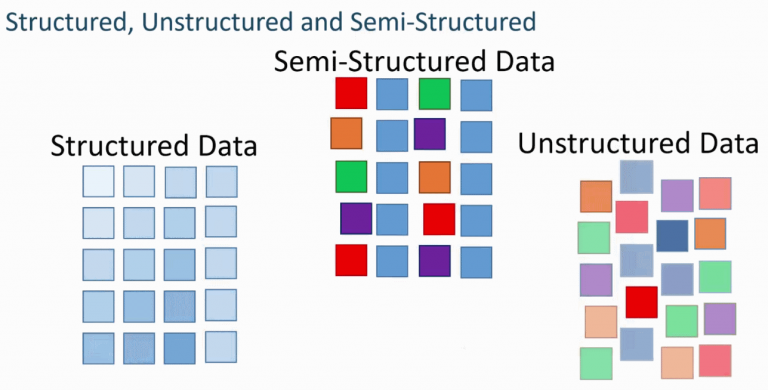
- Los datos estructurados tienen un formato fijo y a menudo son numéricos. Así que en muchos casos los gestionan máquinas y no humanos. Este tipo de datos es información que ya está ordenada en bases de datos y hojas de cálculo almacenadas en bases de datos SQL, lagos de datos y almacenes de datos.
- Los datos no estructurados son información que está desorganizada y no está en un formato predeterminado porque puede ser casi cualquier cosa. Es el caso, por ejemplo, de los datos recopilados de fuentes de redes sociales y puede convertirse en archivos de documentos de texto almacenados en Hadoop, como clústeres o sistemas NoSQL.
- Los datos semiestructurados pueden contener ambas formas de datos, como registros de servidores web o datos de sensores que haya configurado. Para ser precisos, son datos que, a pesar de no estar clasificados en un repositorio concreto (una base de datos), contienen información vital o etiquetas que segregan elementos individuales dentro de los datos.
El Big Data incluye siempre múltiples fuentes y la mayor parte del tiempo es de distintos tipos también. Así que no siempre es fácil saber cómo integrar todas las herramientas que necesitas para trabajar con distintos tipos de datos.
¿Cómo funciona el Big Data?
La idea principal que subyace al Big Data es que cuanto más sabes sobre algo, mejor lo entiendes y te ayuda a tomar una decisión o buscar una solución. En muchos casos, este proceso está totalmente automatizado; contamos con unas herramientas tan avanzadas que crean millones de simulaciones para dar el mejor resultado posible. Pero para conseguirlo con la ayuda de las herramientas analíticas, el aprendizaje automático o incluso la inteligencia artificial, hay que saber cómo funciona el Big Data y configurarlo todo correctamente.
La necesidad de gestionar tantos datos requiere una infraestructura estable y bien estructurada. Habrá que procesar rápidamente ingentes volúmenes y distintos tipos de datos y esto puede sobrecargar un único servidor o clúster. Por eso tendrás que contar con un sistema bien pensado para gestionar el Big Data.
Según la capacidad del sistema, se deberán tener en cuenta todos los procesos. Y en el caso de las grandes empresas, pueden hacer falta cientos o miles de servidores. Como te imaginarás, esto puede empezar a salir caro. Y cuando añades todas las herramientas que vas a necesitar, todavía se encarece más. Así que tienes que saber cómo funciona el Big Data y las tres acciones principales que se necesitan para poder prever el presupuesto de antemano, y crear el mejor sistema posible.
Integración
El Big Data siempre se recopila de muchas fuentes y, como hablamos de volúmenes enormes de información, hace falta descubrir nuevas estrategias y tecnologías para gestionarlo todo. En algunos casos, llegan a nuestro sistema petabytes de información, así que integrar toda esta información en tu sistema es todo un reto. Tendrás que recibir los datos, procesarlos y formatearlos de la manera adecuada para tu empresa y de tal forma que tus clientes puedan entenderlos.
Gestión
¿Qué más puedes necesitar para semejante volumen de información? Necesitarás un lugar donde almacenarla. Esta solución de almacenamiento puedes encontrarla en la nube, en tus instalaciones o ambas. También puedes elegir de qué forma almacenar tus datos, para tenerlos a tu disposición en tiempo real y cuando los pidas. Por eso cada vez más gente elige una solución en la nube para almacenar los datos, porque es compatible con su actual infraestructura informática.
Análisis
Vale, has recibido los datos y los has almacenado, pero tienes que analizarlos para poder usarlos. Explora tus datos y utilízalos para tomar decisiones importantes, como saber qué características son las que más buscan tus clientes o utilizarlos para compartir búsquedas. Haz lo que quieras o necesites con ellos, pero sácales provecho, porque has hecho una gran inversión para instalar esta infraestructura, así que tienes que usarla.
Como ya hemos dicho al hablar de Big Data, siempre hablamos de las grandes V del Big Data. Cuando apareció el Big Data, solo había 3 V, pero ahora son más. Y se les suman otras constantemente según para qué necesites el Big Data. En la próxima sección de este artículo, vamos a ver algunas de las V.
Las grandes V del Big Data
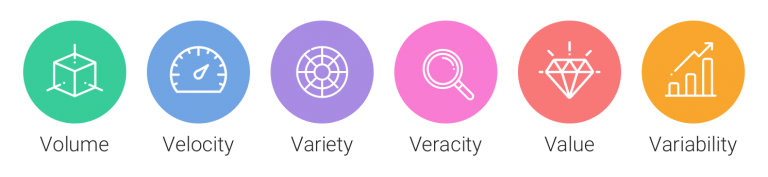
Volumen
Como su propio nombre indica, cuando hablamos de Big Data nos referimos a grandes volúmenes de datos. Así que la cantidad de datos que recibas importa. Pueden ser datos de valor desconocido, como los datos sobre el número de clics en un sitio web o una aplicación móvil. Para algunas empresas pueden ser decenas de terabytes de datos, mientras que para otras pueden ser cientos de petabytes. O es posible que sepas exactamente la fuente y el valor de los datos que recibes, pero aun así vas a recibir grandes volúmenes a diario.
Velocidad
La velocidad es la gran V que representa lo rápido que se reciben y tratan los datos. Si los datos se transfieren directamente a la memoria y no se escriben en un disco, la velocidad será mayor y, como consecuencia, operarás mucho más deprisa y los datos se proporcionarán prácticamente en tiempo real. Pero para esto también hace falta una forma de evaluar los datos en tiempo real. La velocidad es también la gran V más importante en ámbitos como el aprendizaje automático y la inteligencia artificial.
Variedad
La variedad se refiere a los tipos de datos que están disponibles. Cuando trabajas con tantos datos, debes saber que muchos de ellos son no estructurados y semiestructurados (texto, audio, vídeo, etc.). Habrá que procesar aún más los metadatos para que todos puedan entenderlos.
Veracidad
La veracidad se refiere a lo exactos que son los datos del conjunto de datos. Puedes recopilar muchos datos de redes sociales o sitios web, pero ¿cómo puedes asegurarte de que los datos son exactos y correctos? Si usas datos de mala calidad sin comprobarlos, puedes tener problemas. Los datos inciertos pueden dar lugar a análisis imprecisos y llevarte a tomar decisiones equivocadas. Así que siempre debes comprobar los datos y cerciorarte de disponer de suficientes datos precisos para obtener resultados válidos y relevantes.
Valor
Como decimos, no todos los datos citados tienen valor y pueden utilizarse para tomar decisiones comerciales. Es importante conocer el valor de los datos que tienes a tu disposición. Tendrás que establecer una forma de limpiar los datos y confirmar que son relevantes para el propósito que tienes en mente.
Variabilidad
Cuando tienes muchos datos, en realidad puedes utilizarlos con muy distintos fines y formatearlos de distintas maneras. No es fácil recoger tantos datos, analizarlos y gestionarlos de la manera más adecuada, así que lo normal es usarlos varias veces. Eso es lo que significa la variabilidad: la opción de utilizar los datos con distintos fines.
Ya sabemos muchas cosas sobre el Big Data: qué es, los tipos de datos que existen y las grandes V. Pero todo esto no serviría de gran cosa si no sabemos qué se puede hacer con el Big Data y por qué es cada vez más importante.